Python 比起 C 語言等低階程式碼,雖然執行速度絕對慢上數以千倍,但在這個 CPU 效能早已過剩——動輒數 GHz 指令執行頻率——的時代。除非真有龐大資料1需要處理,否則日常使用上,Python 的「慢」還真感受不出來。
但,人生就是這個但是。
我寫的程式,就是慢啊~不知道為什麼,只是跑個簡單的迴圈竟然就要花上 1 分鐘!?
這時候推薦使用 Snakeviz,我們可以用它來找出拖慢 Python 執行效率的罪魁禍首。也就是要來做 Profiling!
範例程式
本文用底下範例程式來說明。這是一支不使用遞迴的斐波那契函式。
def fibonacci(n):
stack = [n]
result = 0
while stack:
current = stack.pop(0)
if current <= 0:
result += 0
elif current == 1:
result += 1
else:
stack.append(current - 1)
stack.append(current - 2)
return result
def main():
fibonacci(27)
if __name__ == "__main__":
main()
看起來很簡單,但在我的 M1 MacBook Air 上大約需要跑 15 秒。超慢!
來分析下。
Snakeviz
安裝
$ pip install snakevizProfiling
使用步驟:
1. 先用 Python 內建模組 cProfile 側錄一下我們的程式2。
$ python -m cProfile -o program.prof fab.py2. 再用 Snakeviz3來查看側錄結果。
$ snakeviz program.prof看結果
畫面主要分成 2 區:左邊是顯示設定,中間的色塊則是 Function Call 時間統計。也就是我們在意的重點!範例程式的分析圖長這樣:

排列方式是由上往下呼叫。也就是:
- Python 執行 Script 的內建呼叫 exec
- 執行 fab.py 第 1 行(Python 模組開始)
- 進入 fab.py 第 15 行(跨號內顯示 Function 名稱,此時是 main 函式)
- 進入 fab.py 第 1 行(fibonacci 函式呼叫)
- ⋯⋯下面依此類推
每個 Function Call 都會統計執行時間,紀錄於各色塊下方。由圖可發現, 15 秒內大部分的時間都花在執行 List 中的 pop 方法!
解決效能瓶頸
知道問題出在哪,就可以來解決了。
Google 一番後,發現問題出在 pop(0) 這操作。每次都需要重新將 List 後面的所有元素往前移動一格,因此相當浪費資源。以範例來說,其實只需要 2 個需求:
- 拿取第一個元素
- 在最後面增加元素
而最適合這 2 種操作的資料結構是 Deque!改寫一下。
from collections import deque
def fibonacci(n):
stack = deque([n])
result = 0
while stack:
current = stack.popleft()
if current <= 0:
result += 0
elif current == 1:
result += 1
else:
stack.append(current - 1)
stack.append(current - 2)
return result
def main():
fibonacci(27)
if __name__ == "__main__":
main()
再跑一次 Profiling。Boom!

這次,不用 1 秒就結束了。搞定!
效能最佳化
真實情況下,不可能每次都像本文範例般如此明顯。更多時候,我們需要自行截取出速度慢的程式片段,單獨寫成一支小 Script 來做 Profiling。並且,通常會長成如下圖般,乍看之下沒有特別花時間的地方。
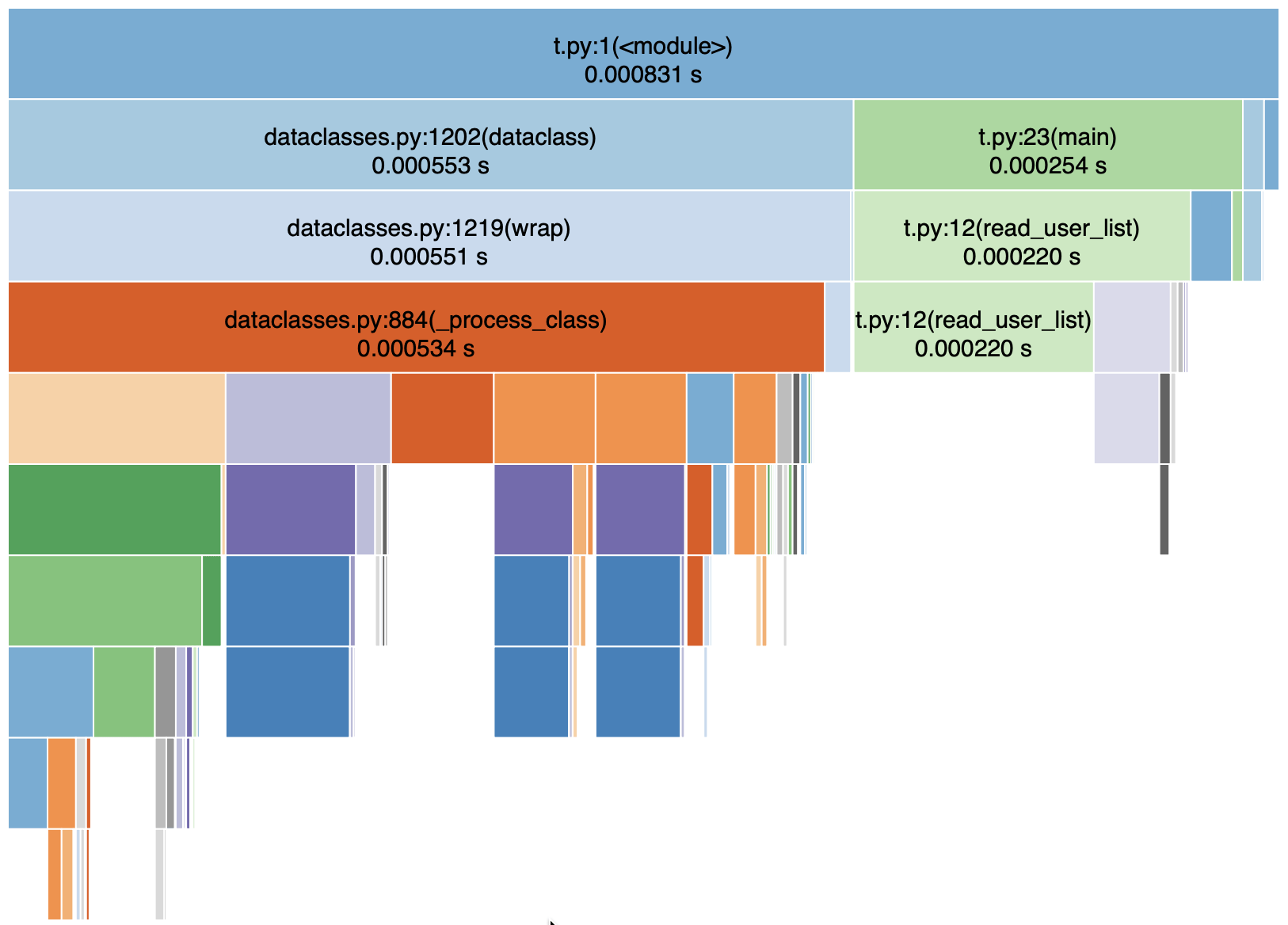
圖中的色塊每個都可以點開。再繼續往下追,看看有沒有不預期花太多時間處理的函式。一個一個點開來檢視,看看有無辦法加速。一些常見的做法是:
- 使用 functools.cache。為經常呼叫的 Function 快取返回值。
- 使用 pickle.dumps 保存肥大 Python 物件,在其他地方直接使用 loads 處理。
- 使用 Threading 或者 Multiprocessing 同時處理。
- 盡可能減少檔案讀取或網路存取次數
- ⋯⋯等等
我想說的是,比起 I/O(硬碟寫入或讀取)、網路爬蟲等常用操作,Python 絕對不慢!雖然會使用 Python 的場景通常都不要求效能。但為了生活我可以忍,可是浪費我們寶貴時間就不行!